



August 17, 2010
Gawain's Jail

TG制下的SB银行SB身份证制度及SB户藉制度
我有一张建行的卡找不到了,中午去建行挂个失。原本以为带上身份证就可以了,没想到啊,没想到,竟然是被银行这帮孙子给气了个半死。没挂成失的原因倒也简单:你的身份证在公安部的系统里没有照片,必须提供额外的带照片印有身份证号的证件来做辅助证明。
我的身份证是02年来北京前办的,有效期十年。在身边的人一个个都换了二代身份证的时候我还一直在使用一代身份证,原因是身份证必须回原藉公安部门办理。可惜我老家在偏远西北,这些年也没几次回家的机会,有回家的机会的时候也没时间去办。抽出时间的时候吧,人家公安部门在放假。
就今天这个问题,有以下几点我是不清楚啊。
- 本人所持证件是否为中华人民共和国的有效身份证件?是。
- 本人所持证件是否为假冒证件?不是
- 本人所持证件是否过期?没有
- 本人所持证件能否证明本人身份?厄,对不起,根据目前规定,必须在公安部的系统内有照片才可以。
公安部系统里没有我的照片,你应该找公安部啊。再说了,公安部门也没向我要照片啊。
还有这个狗逼人民银行,出的这SB规定。你们丫的说改系统就改系统,说让我等屁民回老家办个身份证就办个身份证,说让回老家开个证明就开证明。你们这群大SB,你们知道吗,事情都是被你们这帮狗杂碎给搞瞎了。
每年就因为这极其落后的玩意,误了多少事,你们丫的知道吗?老子在这片被称之为祖国的土地上办个孩子的出生证要回原藉,办个护照要回原藉,换个身份证也要回原藉。你们这些高高在上的狗杂碎们,你们一定会被写在历史的耻辱柱上的。你们反人类进步的做法是会有报应的。
Update: 今天我带医疗蓝本去了,丫们还问我要额外的证件,说是有没有医保卡或者驾照之类的。操了,其他证件一概没有,你们丫的昨天说带医疗蓝本可以的。然后丫们问我谁说的,操,你们的营业员我怎么记得住。男的女的?女的。然后丫给我支到1号台去了,坐了会儿,又给我支回4号台了,操。最终是办理完了。WTF。
August 13, 2010
Gawain's Jail
Set nameserver in dhclient.conf
在FreeBSD上使用OpenVPN的时候不能自动更改DNS,手动更新resolv.conf之后呢,等到DHCP renew地址的时候就再次被改回去了。
解决之道是在/etc/dhclient.conf里写下如下即可保持自行设置的DNS在第一个位置上。
prepend domain-name-servers 8.8.8.8;还有更多关于dhclient.conf的,请参看man手册。
BTW: 自行设定DNS之后就要把内部域名的解析换成/etc/hosts。当然也可以在本地搭一个BIND,把内部域名给forward到内部DNS去(此王道也!)。
Use CUPS on FreeBSD
最近把工作机从Mac换到了FreeBSD之后,有许多在Mac OS X和Windows这些成熟桌面操作系统不需要关心的问题,都需要手工去解决,在一些人看来这就是折腾,其实在我看来这也确实是折腾。不过那又怎样,我们就是不折腾不舒服司机( cc @delphij @quakelee)。
先安装printer/cups,然后在/etc/devfs.rules里写上如下:
[system=10] add path 'unlpt*' mode 0660 group cups add path 'ulpt*' mode 0660 group cups add path 'lpt*' mode 0660 group cups自然的还要在
/etc/rc.conf或者/etc/rc.conf.local里写上cupsd_enable="YES"
在这些做完了之后呢还要在/etc/make.conf里写上如下
WITH_CUPS=YES CUPS_OVERWRITE_BASE=YES WITHOUT_LPR=YES这样一来呢,Ports里有支持CUPS的软件在安装的时候就可以自动挂上CUPS的支持了。然后要做的事情就是buildworld了。这样就会把lpr替成cups的lpr。
说到这里我就顺嘴带几句别的。公司使用的是Fuji Xerxo DocuCentre-II 3005打印机,前几天我在Mac上设置的时候没有发现相关的驱动支持,我就去Fuji Xerxo的网站上下载了一个Mac OS X 10.5 / 10.6 Driver,杯具就是从这里开始的。那天下午我试这个驱动试了多次,浪费A4纸4张,全是乱码。后来问了个使Mac的同事,告诉用Generic PCL Laser Printer驱动就可以了,操勒,不但能正常打印,还可以双面。Fuji Xerxo的家伙们,即然你们做出了这么牛B,这么标准的产品,那还提供那个废柴驱动干啥,WTF。
Link: CUPS on FreeBSD
August 12, 2010
Gawain's Jail
调教fonts.conf的过程
继续说字体渲染的事。在Unix下使用Xorg和FreeType时,可能要花一些时间来调教一下,方能得到一个可以接受的结果。这也是使用Windows和Mac OS X的用户几乎不用关心的事情。
在fonts.conf的调教过程中一定要清楚的知道自己想要的效果,并且对字体渲染过程要有一个简单的了解,否则还是照着别人的抄一份吧。
对于中文用户来说首要的问题应该是字体的fallback,所以应该安装一些中文的字体,比如x11-fonts/wqy。
然后再来看这些字体的优先级别。默认到底是宋体、黑体还是圆体都想根据自己的喜好来设定一下。我这里就选了文泉驿的米黑。不过这里应该多说一句的是要区别Sans, Serif和Monospace这几个字体类型。
然后再来看Hinting的设定,默认使用的HintStyle是什么。
- hintnone: 就是不改变字体设计的做法,但是对有些TTF字体要注意一下,应该打开一些TTF的auto-hinting设定。
- hintslight: 一般而言对字体的hinting是基于x轴和y轴的,但是slight设定只会对y轴做hinting。
- hintmedium和hintfull是更加激进的两种设定,对于屏幕文字的可辩识程度是增加了。但是我并不喜欢这个设定,也许Windows的用户会喜欢这两种设定。要特别注意的是微软出品的一些TTF字体是很依赖hinting技术的,所以对微软出品的字体最好是设置为hintfull。
调教的过程会设置Sub-pixel Rendering,在fonts.conf里就是rgba的设置。某些字体应该是不适合开Sub-pixel的,比如文泉驿的米黑就属于这一类。这样的字型要是开了Sub-pixel,看起来就像是加了个有颜色的边,而且不是每个边都有。所以对于这样的字体开GrayScale Anti-aliasing就可以了。GrayScale和Sub-pixel Rendering要干的事情基本一样,就我个人而言我比较喜欢用Anti-Aliasing。,但是效果是不同的,我在Mac OS X上做了测试,在开启Sub-Pixel Rendering的情况下字体明显要比GrayScale的清晰,但是我在FreeBSD下的设置很是不尽人意,字体边上的颜色太明显了,反而有一种炫目的感觉,这可能就是之前我不喜欢Sub-Pixel Rendering的原因吧。总之在对比之后,只能退而求其次,只使用GrayScale了。
如此看来,调教fonts.conf的过程是比较麻烦的,因为对不同的字体要进行不同的处理。所以呢,我偷懒从别人那个抄了一个,再改一改就开始用了,现在基本满意。另外呢,听说Apple关于字体渲染的算法专利已经过期了,并且之前的那个FreeType分支也合并了,Unix屁民们使用上Mac级别的字体渲染,也为期不远了。
update: 和@jjgod聊天之后,我在Mac下对比了下GrayScale和Sub-Pixel Rendering的差别,在LCD下应该开启Sub-Pixel Rendering,但目前我的设定似乎没有达到预期的效果,所以先使GrayScale,等看完了那些鬼佬们写的文案再来调整吧,理论知识的不足,就是盲目啊。
Links:
- 我抄的fonts.conf
- Joel Spolsky: Font smoothing, anti-aliasing, and sub-pixel rendering
- Github:Gist 我的fonts.conf
关于字体的显示技术笔记
今天整了一下公司的工作电脑,配置桌面的时候看字体的显示怎么也没有Mac OS X下的那种感觉。调了半天也不尽人意,后来@jjgod同学给了个关于字体显示的论文,做点笔记,还请知晓的相关技术的朋友指正。
在显示器上字体大概有三种技术。
- Hinting
- GrayScale Anti-aliasing
- Sub-pixel Rendering Anti-aliasing
是把字体的形状发生一变化,以适应计算机显示器上像素点,以此呢来提高在低分辩率的可识别能力。
这是利用显示器的灰度明暗产生的字体显示技术,是在字体形状的边缘产生一些有明有暗像素点,骗过人眼使得字体的形状看起和设计的差不多。
这是要有显示器支持的一种技术,基本上是应用在LCD上的。原理是利用LCD显示器的每个像素点都有rgb三个点混合而成,控制rgb这三个点的亮度和色品以达到一种类似GrayScale Anti-aliasing的效果,实际上是从效果上提高了水平分辩率。
update:和@jjgod聊过之后,纠正了我对AntiAliasing概念的混淆,关于AntiAliasing的名词有GrayScale, Sub-pixel Rendering和Sub-pixel Positioning,这几个概念是不同的。
参考:
August 10, 2010
HYRY 's Blog
《用Python做科学计算》8月进展
到目前为止的本书进展情况:
- 《用Python做科学计算》的实例网站 已经上线。读者可以通过此网站查看本书的最新实例源程序和它们的运行结果图,并且可以对每个程序进行评论。
- 基本完成的TVTK章节的修改工作。补充了一些OpenCV和NumPy方面的内容。
- 回答问卷调查的读者数已经超过了200位。
- 制作了一个介绍本书编写工具的幻灯片:http://hyry.dip.jp/files/scipybook-tools.pdf
8月份的写书计划:
- 从明天开始的5连休中,制作一个使用Leo和Sphinx等编写书籍的演示。对目前完成的章节的进行初步校对。
- 给所有的实例源程序添加简单的说明。
- 完成Mayavi一章。
August 09, 2010
Gawain's Jail
网易的镜像添加了FreeBSD的镜像
去年3月的时候,可能网易镜像刚刚发布,我给[email protected]写了封信,希望他们能加上FreeBSD的portsnap镜像和mastersite的镜像。今天我收到了他们的回信说是已经添加了ports和package的镜像。
其实我并不是说网易过了一年多才回这封信,而是觉的虽然时间久了一点,但网易的这种贡献和投入依然是值得赞赏的。
Link: 网易的FreeBSD镜像,另附上/etc/make.conf的设置。
MASTER_SITE_OVERRIDE?=http://mirrors.163.com/FreeBSD/distfiles/${DIST_SUBDIR}/
July 30, 2010
Gawain's Jail
Statistics From Woodpecker.org.cn
刚才看了下Woodpecker.org.cn的Google统计,有一些数据可以拿出来看看。
- 日均访问量(Vistors/Day):873.71 Visits / Day
- 日均PV:3000
- 平均停留时间:00:03:42
- 浏览器的前三是:
- Internet Explorer(33.95%)
- 8.0(45.98%)
- 6.0(34.74%)
- 7.0(19.25%)
- Firefox(33.68%)
- Chrome(25.61%)
- 操作系统的排名前三是
- Windows(82.18%)
- XP(69.32%)
- 7(24.08%)
- Server 2003(3.27%)
- Linux(14.13%)
- Macintosh(3.22%)
- Intel 10.6(87.83%)
- Intel 10.5(10.79%)
July 24, 2010
Gawain's Jail
bash里关于string相关的处理
- 取字符串的长度:
${#VAR}
# a="HelloWorld"
# echo ${#a}
10
${VAR:POSITION}或${VAR:POSITION:LENGTH}
# a="HelloWorld"
# echo ${a:5}
World
# echo ${a:4:3}
oWo
${VAR#SUBSTRING}和${VAR%SUBSTRING}
# a="HelloWorld"
# echo ${a#*o}
World
# echo ${a%o*}
HelloW
注:#是从前向后,并且*号是紧随着的,而%则是从后向前匹配。*号是放在最后的。
${VAR#SUBSTRING}和${VAR%SUBSTRING}
# a="HelloWorld"
# echo ${a#*o}
rld
# echo ${a%o*}
Hell
${VAR//PATTERN/REPLACEMENT}
# a="HelloWorld"
# echo ${a//World/Earth}
HelloEarth
expr STRING : REGEX# a="HelloWorld" # expr $a : ".*o" 7
注:这里的REGEX从名字上就说明了是一个正则表达式。
Update:详细请参考
- Advanced Bash-Scripting Guide: Table B-5. String Operations
- The Geek Stuff: Bash String Manipulation Examples - Length, Substring, Find and Replace
July 19, 2010
Gawain's Jail
Data Center基础设施革新
来自James Hamilton: Data center infrastructure innovation
- 革新的步调----革新的步调正在加快。高度关注基础设施的革新可以降低成本、增加可靠性并且减少资源的消费,最终的目的就是降低成本。
- 钱都花哪儿了?----
- 54%花在服务器上,8%花在网络上,21%花在配电上,13%在电力上还有5%花在其他的基础设施上了。
- 34%的成本与电力有关。
- 电力成本有上升的趋势。
- 云效率----服务器的使用率在咱们的工业里是10%到15%。
- 避免在基础设施中使用漏洞。
- 把工作拆成小份,并且尽可能的将他们排入队列。
- 配电----11%到12%的电力消耗在了配电的过程中。一些最小化电力消耗的规则
- 把电力都卖出去,只要电力允许就放置更多的服务器。
- 避免使用变压器。
- 增加电力转换的效率。
- 高压越接近负载越好。
- 使用效率高的电压整流设备。
- 高压直流是一个小的潜在利益。
- 机械系统----一个可以节省空调的环节。
- 什么是可以被改进的?冷却塔,热交换,泵,蒸发器,压缩机,冷凝机等。
- 上述这些系统的效率取决于对不同温度的需求。
- 冷热系统分离
- 增加服务器的运行温度。
- 通常在61到84
- 电信标准是104F(40C),游戏行业要更高一些。
- 温度
- 限制到高温运行的因素
- 避免整体直接澎涨冷却
- 过滤微粒和化学污染
- 网络安排
- 目前的网络是超订了
- 强制放置有序
- 目标:所有点到数据中心的距离是一致的。
July 17, 2010
Gawain's Jail
关于打孩子的看法
当爸爸之后有时候会和老婆聊聊孩子将来的教育问题,必然的就会聊到打孩子的问题。刚才洗脸的时候又突然想起这个事情,想先撂句话在这儿。就是无论孩子将来做了什么事情,都不要去打他。暴力是不能解决所有问题的,两个理性的人之间应该是可以坐在一起通过交流和讨论来解决问题的。
性能问题前十
来自DynaTrace's Top 10 Performance Problems Tanken From Zappos , Monster, Thomson and Co。
- 太多的数据库请求
- 请求的数据多于实际使用的数据。
- 同样的数据请求多次。
- 多次的请求一个必然的结果集
- 同步走向死亡
- 过多的远程调用
- 错误的使用ORM
- 内存泄漏
- 成问题的第三方代码或组件
- 贪婪的占用稀缺资源
- 肥胖的前端
- 错误的缓存策略导致额外的垃圾回收
- 间断性的问题
- (额外送的)昂贵的序列化
在一个请求或事务中数据库请求太多。具体有三种现象:
同步是一种保护共享数据的重要机制。但是过度的代码同步就会引发性能问题,这种问题在单机的时候并不明显,但是在一个高负载的环境下就难以持续了,最终的结果就是死亡。如何确定同步问题,可以把程序的CPU时间和总体执行时间在递增负载环境下做测试对比,就会发现CPU时间几乎是一定的,但是总体执行时间是随负载增加而快速增涨的,那就是说这个程序在同步上是有问题的。
许多的库都是一些远程调用,对于程序员来说,本地调用和远程调用在程序上并无差别。但是不要忘记了远程调用的额外成本,比如:传输时间、序列化、网络流量以及内存使用等等。
ORM从开发人员手里接过了载入和存储数据的重担。ORM的框架一般都有许多的设置以供优化,在使用时候如果使用了错误的设置,就会导致一些不可预见的性能问题。所以在使用框架的时候对于其设置项要真正的了解其内部的工作方式。
垃圾回收并不能阻止内存泄漏,所以尽可能快的释放对象引用是非常重要的。
代码是人写的,是人写的就会有问题,但是问题有多有少。所以在引入第三方代码或组件的时候最好是深入检查一下,以免从A产品的开发人员演变成B组件的捉虫队。
像内存、CPU、I/O、数据库啥的都是稀缺资源,所以就别占着矛坑不拉屎(这也是人品中重要的一项,我相信一个人品好的人写代码的时候也会这么做。)。
太肥的东西总是要避免的,不管是吃、看还是用。
缓存对象到内存是为了避免重复的数据库请求。但是如果把太多的数据都缓存到内存或是数据对象是频繁被更新的,那这样的缓存策略带来的问题就是要做更多的垃圾回收工作。
这种问题较难发现,通常出现在特别的输入或是某个确定的负载情况下。这只能是尽可能的做全面的测试,从功能到负载和性能都覆盖到,这样就尽可能早的把这种给问题给揪出来,从而不影响到真实用户。
在现在的Web应用中序列化随处可见,REST大行其道,数据对象要序列化之后再通过接口才能送出去。有序列化就有反序列化,这种开销是对称的,所以要尽可能快速的处理这两个问题,而且还要考虑到其序列化后数据的大小,内存占用等问题。
June 25, 2010
Gawain's Jail
2010年的Mac软件清单
每年几乎都要来这么一次,最近想整理一下的原因是周围有两个同事相继加入Mac党,帮他们安装设置了一些工具。所以就顺手也整理一下:
- 网页浏览 主要使用的还是Safari,同时也挂上了Glims。安上Firefox的主要原因是Y!slow和Firebug,同时为了有更好的界面效果,还搭上了foxdie.us。
- 网络下载 FTP的主要工具是Cyberduck和在Terminal.app使用的ftp命令。cURL则是一个下载以及测试的利器。
- 文本编辑 虽然Textmate一直不思进取,2.0杳无音讯,跳票情况超过暴雪,但是今年还是团了一个License,确实是码农必备。另外在写中文文档的时候也会用到TextWrangler。
- 文档编写 公司里有太多的人使用Word和Excel了,所以也会安装一套M$的Office 2008来用。文档的编写一般是趋向于纯文本方式的,如果有格式要求我更趋向于使用TeX,自然也就会安一套MacTeX来用。安装iWorks主要是冲Keynote去的。
- 绘图处理 OmniGraffle绝对是Mac上的超牛B软件画图软件。对于照片的管理还是用了自带的iPhoto,虽然以前下载了Aperture回来试用,但是对于我这样的傻瓜用户还是有些太高级了。一般的裁剪工具就是自带的Preview.app。思维导图则是MindNode.app比较好使。
- 影视娱乐 看电影必用的工具是Perian,VLC和Movist。一般情况下会先用QuickTime来播,如果不行就换Movist,再不行换VLC。在家接上电视的时候也会用Plex来放电影,不过这个情况要少一些,可能等我在家里搞起一个电影库的时候就有用了。RealPlayer已经从我的安装清单里去掉了,下载电影的时候也基本上不下RMVB了。
- 聊天通信 我平常几乎只开iChat挂Google Talk,偶尔会开一下Adium和QQ。
- 杂项
- Nally.app是读BBS的利器
- The Unarchiver.app可以通吃所有的打包档。包括rar的字符集问题处理的都不错。
- Tweetie.app是发推利器,而且支持民间RT。
- iCompta.app来记帐是节源的好工具,不过要坚持下来才可以。
- HandBrake.app来转档给iPhone使。
- Evom.app也是转视频档给iPhone使的工具。
- CoRD.app可以连接Windows远程桌面。
- iChm.app可能是Mac上最好用的chm阅读器了。
宝宝叫白袭明
到今天宝宝出生已经一个月了。其实从出生前就一直在想给宝宝起个什么名字,结果到宝宝出生都没能定下一个名字来。头一段时间我还在推上请大家给赐个名。大家给出了不少的好名字,因为宝宝是早晨生的,老黄给起了个白晓天,@zoomq给起了个白晓生,同事@xklxkl给起了白慕天。更有朋友@heqian建议叫白展堂,这样比较响亮。
家人在讨论的过程中也一直没有什么定论,有一天我翻《老子》,到了第27章的时候,看到一个词叫袭明。
善行无辙迹。善言无瑕谪。善数不用筹策。善闭无关楗而不可开。善结无绳约 而不可解。是以圣人常善救人,故无弃人。常善救物,故无弃物。是谓袭明。故善 人者不善人之师。不善人者善人之资。不贵其师、不爱其资,虽智大迷,是谓要 妙。对于袭的释义,有的取"双重"之意,有的取"承袭"之意,我觉的两者兼有吧。明的释义基本上都解释为"聪明"。
袭明这个名字,老婆觉的这个袭字太过锋芒,我父母则觉的"明"字与我的太爷爷辈的名字有冲突,入不了家谱(按家谱应该叫白茂*)。但是过了一段时间也没能想到更好的名字,所以也就把这个名字定下来了。
孩子还有一个小名叫丁丁,是由他的姥姥和姥爷在他还没出生时起的一个名字演化来的----白丁,对,就是"往来无白丁"的那个白丁。
June 24, 2010
HYRY 's Blog
《用Python做科学计算》6月进展
OpenCV一章基本写完成了,有接近40页的篇幅。在编写此章的过程中,发现了pyopencv的几个BUG,已经提交给其作者了。等新版本发布之后,再进行成本章的收尾工作。
接下来在进入最后一章SymPy的编写之前,准备先将其它章节缺失的部分补齐。从下个星期开始:
- 完成Chaco一章
- 合并TVTK和Mayavi章节,完成Mayavi部分,对TVTK部分进行删减
我将每天在哲思社区的论坛中更新每天的进展情况:
由于此社区需要邀请才能注册,如果你有兴趣参加讨论的话,可以给我发邮件:ruoyu0088 at gmail.com,我将发送邀请码给你。
June 09, 2010
Gawain's Jail
WWDC放出的和我想要的
WWDC的keynote已经过去了,直到今天早晨我才在iPhone上看完视频。总体来说我想要的东西,Apple没发。
iPhone 4的过人之处有三:
- 强悍的电力,300小时待机啊,300小时啊。
- 高精细的屏幕,326ppi啊,326啊。
- 三轴的陀螺仪,三轴的啊,三轴啊。
我本以为Apple为回应Google IO的动作把MobileMe给免费了,再搭上个无线同步。这种事情也许将来有吧,但是这次是没出。我猜没出的原因如下:
- 苹果目前还无意指染云端。虽然苹果一定在搞云端工程,但现在可能不是推出的时候。
- 云端同步的带宽还不够快。每次同步都backup,如果为了云端同步而让同步过程速度变的更慢,老乔是不会答应的。当然现在已经很慢了。
- 苹果目前的技术整合能力还没有到这一步。收了lala之流的公司还没来得及完全整合。
- 在线的音乐流服务。
- 在线的高清电影流服务。
- 更高速的网络。
- MobileMe准备好免费接纳现有的iPhone用户。
就现在Apple放出的玩意来看,比Google弱的事情主要在TV上,和Google TV相比Apple TV真是太烂了。Android现在能直接把视频流推给Google TV。iPhone你是要到iOS 5能支持还是iOS 4.x就能支持呀,还是等你出了Apple TV二代才行啊。说实话推视频这个功能真的是超赞的,有赤裸裸的需求的。
Apple,自上次Google IO之后,我觉的你还得再加把劲才做的稳头把交椅。
June 02, 2010
Limodou

Flask简单分析
Flask的作者就是Werkzeug的作者,也是Jinja的作者。而Uliweb的底层是使用Werkzeug来做的。因此从一些功能和模块的使用上,Uliweb与Werkzeug是类似的。那么下面是我粗浅看了一下Flask的文档和某些例子了解到的一些东西。当然,从我的角度,可能会主要从框架功能和设计上来了解,并且有可能会与其它的框架进行对比分析。
1. 基本结构
的确是一个微型框架!
为什么这么说?因为它的功能只是完成了基本Web的功能。没有ORM,因此你可能要使用sqlalchemy。有模板(使用jinja),有Session,有Cookie(因为Werkzeug都带这些,当然我个人认为功能有限)。做简单的Web应用够了。目前没看到有命令行工具。调试运行的话就可以在主程序的__main__中来写。因此和web.py更为接近。不过web.py有简单数据库的封装。有约定的运行目录,约定了模板和静态文件存放的位置。没有app结构的默认支持。没有静态config文件定义。没有看到middleware的支持(不过看到有after_request之类的decorator不知道是不是类似的东西)。
2. 开发
提供了象url_for之类的url反向映射方法。提供app.route()来定义url。这两点和uliweb是一致的。对于模板,提供了类似django的render_to_template的方法,需要显示提供模板名称。而uliweb和web2py则支持缺省的模板名称。url对应的处理采用函数方式,比如接近MTV的开发模型。提供了类似web2py的message flash的机制(即在模板中可以显示一个返回的信息),这是通过在模板中预定义相应的显示实现的。view函数中不需要显示定义request, response,可以从Flask中导入这些对象在view函数中使用。这一点接近uliweb。不过uliweb导入request只是可选的,uliweb会自动在view的环境中注入一些对应供view方法直接使用。
3. 扩展
Flask已经提供了一些功能的扩展模块,如open_id的支持。是很好的学习材料。
4. 文档
的确不错,内容详细。
现在看一看uliweb,的确从Flask可以学到不少东西,比如:扩展性,还可以从Flask中学到一些扩展模块。文档,需要进一步提高。Message Flash的支持。当然uliweb对Flask要大很多,比如:app结构的支持,ORM的支持,Form支持等。这些在Flask不是内置的,需要使用其它的库。不过,因为它是一个微型框架,所以这些反而可以认为是灵活性的一部分,不是必须的。而uliweb则更多象web2py和django一样,希望减少用户自已的选择,至少可以先有一个默认的可以使用。
以上是对Flask的一些简单了解和体会,供大家参考。
update 2010.6.2 刚才又看到Flask是支持外部config的定义的,而且支持的方式还挺多,在此更正一下。配置项的名称规则和django的一样,必须是大写的英文标识符。
类别:Uliweb 查看评论
May 25, 2010
HYRY 's Blog
PyGeo重生
PyGeo是一个Python的交互式立体几何库,它的作者因事故于2007年去世,到目前为止似乎没有人对它进行维护。由于它使用VPython3和Numerical Python两个已经过时的库,已经无法在Python2.6上运行。
PyGeo项目地址:http://pygeo.sourceforge.net/
几个月前,为了写进《用Python做科学计算》一书,我花了一些时间将其进行改造。实数部分已经改造完毕,目前已经能使用VPython5和NumPy,并且还可以自定义控制面板。
下载地址:http://hyry.dip.jp/files/pygeo.7z
目前已经不打算在书中添加PyGeo方面的内容,等本书告一段落之后,准备写一些关于PyGeo的教程。
下面是使用新的PyGeo制作的激光反射模拟:

May 21, 2010
HYRY 's Blog
《用Python做科学计算》5月近况
到今天为止,本书共收到100份问卷调查,历时1个半月。
5月份添加了SWIG介绍,完善了TraitsUI一章的内容,为matplotlib添加了坐标变换相关的的介绍。其它各章节也有小的改动。
本书正文部分目前已经到了408页, 预计最终成书应该在500页左右。由于本书目前以A4纸张排版,并且尽量少留页面余白,因此如果转为16K纸张的话,可能还能多出几十页。
最近开始为程序和其说明段落之间添加标号,方便读者对照阅读。目前完成了前4章的修改,其效果如下图所示:

下面是今后需要完成的部分,各章节的校对工作将和编写交叉进行。
1. OpenCV整章
2. SymPy整章
3. 整理TraitsUI,Chaco,TVTK等章
4. 添加Mayavi的应用程序一节
5. 添加ctypes的基础介绍
6. 添加更多的SciPy子模块介绍
7. 数据和文件一章添加视频图像数据相关的介绍
从下星期开始编写OpenCV一章,将以pyopencv模块介绍OpenCV 2.1的基础用法,预计篇幅为35页。由于OpenCV过于庞大,这将是一件十分费事的事情,希望能在7月份之前完成。
May 18, 2010
Limodou
使用Ulipad进行正则替换处理
Ulipad中的查找替换是支持正则式的,也许有人还不知道。下面是一个案例讲述了如何在Ulipad中进行正则式的查找和替换。
故事是这样的:
网友Joe问我一个问题,有没有可以支持正则替换的工具,我说,有啊,EditPlus和Ulipad都可以。Joe是因为从论坛里直接拷贝了一些文本,但是有一些无用的信息想去掉,形式为:
UID
2809652
阅读权限
10
在线时间
664 小时
最后登录
[略]
* 个人空间
* 发短消息
* 加为好友
* 当前离线
可以基本认为在"UID"和"* 当前离线"之间的内容都是无用的,可以删除。但是因为这样的地方很多,手工处理很麻烦,于是Joe就想到使用工具来完成这件工作。于是我让Joe把内容存成文本发给我,我使用Ulipad进行了简单地加工。具体的文本内容就不贴了,很大,只是说明我是如何做的。
首先是验证正则式如何写。直接写还是有难度,于是先打开Tools->Live Regular Expression,这是一个动态测试正则式的工具(不知道有几个人知道并用过)?

可以看到输入的正则式,同时右侧设置了"Multi Line"和"Dot All"标志。匹配上的结果在右下角,内容比较多,拖动可以看到完整的,符合我们的要求。
然后点"Create",生成最终的正则式,结果为:
re.compile(r"UID.+?\* 当前离线", re.S|re.M)
然后按Ctrl+H打开查找替换面板:

这里输入的是 "(?ms)UID.+?\* 当前离线",前面"(?ms)"是在正则式中设置re.M和re.S标志用的。注意,这里选中了后面的"Regular Expression"标志,因此这时就是进行正则式的处理了。如果你按下箭头(查找框右边的绿色向下的箭头)则可以先进行查找。上图的绿色文字就是找到的结果,看一看没问题。然后点"Replace all"进行全部替换就好了。
后来发现还有一些多的空行,于是又写了一个替换,把"\s*\r\n(?:\s*\r\n)+"替换为"\r\n\r\n"即可。它的作用是把多个空行(每个空行前面可以有空格)替换成一个空格。
经过上面的处理,文本就处理好了。
类别:Ulipad 查看评论
May 11, 2010
Gawain's Jail
性能问题
记点笔记:High-Performance Server Architecture
性能问题一般因以下四个原因而起:
- Data copies(数据复制)
- Context switches(上下文切换)
- Memory allocation(内存分配)
- Lock contention(锁争用)
为避免Data copies,作者使用的方法是间接使用和通过buffer descriptor来代替buffer pointer,每一个buffer descriptor由以下部分构成:
- A pointer and length for the whole buffer. 一个指向整个buffer的指针和大小。
- A pointer and length or offset and length for the part of the buffer that's actually used. 一个指向buffer实际使用部分的指针和大小或偏移量及大小。
- Forward and back pointers to other descriptors in a list. 指向其他描述符的向前及向后的指针列表。
- a reference count. 一个引用计数。
HS: sify.com的构架
刚才看过了High Scalability的新文:SIFY.COM ARCHITECTURE - A PORTAL AT 3900 REQUESTS PER SECOND。构架里有许多有意思的地方,他们在GFS上存储所有数据,没有DB,没有NoSQL,而是使用Apache Solr来做数据的索引。使用了Drools这个rule引擎来处理缓存过期的问题。文章的最后把他们在构架进化过程的问题也抛出来了,这一点很不错,弯路谁没走过,把这样的经验分享出来是相当不错的。 从抛出来所遇到的问题和解决方法来看,系统重启以解决还是相当的普遍。
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=ae2c25f9-de37-4918-851f-760b6316b98b)
May 05, 2010
Limodou
web2py中的block支持
这两天web2py中的Thadeus Burgess与我讨论起uliweb中的模板,他想做移植,因为uliweb中的模板是来源于web2py的,但是经过我的修改支持block语法。不过就不再支持原来的{{include}}的。Thadeus Burgess进行了比较大的修改,现在已经被Massimo合并到web2py的trunk中了。对web2py感兴趣的同学可以去试试了。现在的web2py的模板既可以象以前一样使用,也可以使用block了。不过我没有把这个新的代码合并到uliweb中,因为有些功能还是不太一样,所以应该不会合并的。
类别:Python 查看评论
April 28, 2010
HYRY 's Blog
长假写书计划
黄金周有7天的休息时间,为了不让这几天时间浪费掉,准备完成《用Python做科学计算》一书中的如下章节:
1. 完成SWIG部分,对用C语言编写扩展一章进行校对
2. 将FFT演示程序一章合并到频域信号处理中
3. 完成Mayavi的相关章节,并补充TVTK章节的部分内容
4. 补充traits制作界面一章的部分内容
希望能够顺利完成。
April 10, 2010
HuangYi 's Blog

博客搬新家
鉴于blogger常年在墙外,严重影响了发贴的心情。终于搭建了自己的博客。 http://www.yi-programmer.com/blog/ 博客的成功运转跟下面这些光辉的名字是分不开,向创造这些东西的大牛们表示致敬,谢谢git,谢谢make,谢谢python,谢谢docutils,谢谢mako,谢谢pygments,谢谢latex。
April 05, 2010
HYRY 's Blog
《用Python做科学计算》问卷调查和试读
通过分析近一个月的留言,以及搜索《用Python做科学计算》在网络上的一些反应,我总结出以下两点:
- 用Python做科学计算的潜在读者数量不大
- 阅读过电子版,对这方面很感兴趣的朋友都愿意购买纸质书
因此出版此书还有些困难,但是我不会放弃出版的努力。出版时间对我来说不是问题,但是可能会对想尽早读到此书的朋友们造成不便。为了让真正需要阅读此书的朋友尽早能读到,我决定有条件地向读者公开PDF电子版和源程序。
请将下面的问卷调查发送到我的邮箱(ruoyu0088 at gmail.com),邮件主题中请使用“《用Python做科学计算》问卷调查”。我会根据回答情况,将当时最新的PDF文件和源代码发送给你(忙的时候,可能会需要一个星期的时间)。请不要将您收到的电子版传到网络上,这样做会影响出版社出版本书的决定。(《可爱的Python》一书的电子版也有半年的沉默期)
1. 如果本书出版,您会购买几本?( 小于等于0将收不到电子版)
2. 为了防止电子版在网络上被公开,您同意我们将您的邮件地址放在电子版的每页页眉之上吗?(不同意将收不到电子版)
3. 您会将电子版中发现的错误反馈给我们吗?
4. 您会为了学习本书安装并下载Python(x,y)吗?(有400多Mbytes,完全安装之后占用1G硬盘),或者您愿意自己逐个安装Python的扩展库?
5. 请评价一下您的Python水平?
6. 您主要做哪方面的科学计算,或者对哪些方面感兴趣?
7. 请估计在您的同事、同学或者朋友中,有几位可能会购买本书?
8. 您的职业是?
9. 您的姓名、年龄和所在地?
10. 对本书您有何意见或者建议?
March 25, 2010
Gawain's Jail
Sync Contacts Calendars with Mac, Google and Windows Mobile Phone
因为我的手机坏了,就从朋友手里借了个Dopod S1来用,但是和Mac同步数据就成了一个问题了。刚开始用SyncMate来同步,也还可以,但是最近总也是连不上,无法同步。找了找看到Google对Windows Mobile的同步支持也不错,就可以使Mac同步到Google,Google再同步到Windows Mobile,这样还省得带数据线了。
Mac OS X 10.6.2的Address Book可以直接和Google Contants同步,而10.5.x必须要有一个iPhone/iPod和iTunes同步才可以和Google同步(好奇怪的策略),没有iPhone/iPod的话就要Hack一下了,具体方法看这一篇。10.5和10.6的同步的范围有一些差别,10.5是同步Gmail里的All contacts,而10.6里则是只同步My Contacts部分。不过这个和Google的同步好象不太靠谱,所以就有了这一篇,其中有一个回复说明Google Sync Client是作为一个App client存在的,必须搭上MobileMe或者其他同步Address Book的服务才可以进行同步。下面两行就是把Google Sync Client换成了server类型,也就直接可以使用iSync的Sync Now来同步了。
sudo defaults write /System/Library/PrivateFrameworks/GoogleContactSync.framework/Resources/ClientDescription Type 'server' sudo chmod 644 /System/Library/PrivateFrameworks/GoogleContactSync.framework/Resources/ClientDescription.plist也可以用命令行来手动的触发同步。
/System/Library/PrivateFrameworks/GoogleContactSync.framework/Versions/A/Resources/gconsync --sync gconclid --register 1 --username [email protected] --password PASSWORD --syncmode fast通过Console.app可以看到sync产生的log,来确认同步是不是在正常进行。
默认的同步间隔是1个小时,可以通过修改~/Library/LaunchAgents/com.google.GoogleContactSyncAgent.plist文件来改变同步间隔。
<key>StartInterval</key> <integer>900</integer>
如此一来Mac和Google的同步就搞定了。而Windows Mobile和Google的同步就简单多了,看这一篇就可以了。
Update: 在Google Contacts里写新增用户的时候要写成"名 姓"的格式,名在前,姓在后,中间有空格。这样同步到Address Book里的时候姓和名的位置才是正确的。
再说说Echofon和Tweetie
Echofon近期都作了很多的更新,基本上已经满足我的需求了。Tweetie最近也出了一次更新支持了官方RT,但是Echofon和Tweetie对于官方RT的处理是不同的。Tweetie上官方RT会被翻译成民间RT的模样,如果进行reply和repost的操作是针对RT这条Tw的人,并不是这个Tw的原始作者。而Echofon对官方RT的处理就是reply和repost都会针对Tw的原作者。相比之下Tweetie的风格更好一些,熟人之间更容易展开讨论。
March 18, 2010
Gawain's Jail
又败家给MBP添了两条内存
今天又败家给MBP添了两条DDR3-1066,单条2G的内存。花费660大洋。
加了内存之后,再一次的验证了真理:花钱买回来的性能真不是盖的。开虚拟机那个速度快呀!原本想等到单条4G的便宜了再买,等了半年还是无望,算了还是先买两条2G爽爽吧。
March 10, 2010
HYRY 's Blog
《用Python做科学计算》近况
大约有两个月没有更新《用Python做科学计算》一书的电子版了。这两个月中,本书的内容仍然在持续增改。目前正在考虑出版此书,因此直到解决有关出版方面的问题,电子版将可能一直不进行更新。书出版后,可免费下载书中删除的章节以及源代码。
下面是这两个月更新情况。
编写工具方面:使用Bazaar进行版本管理,编写Leo脚本方便快速输入
书的内容方面:增加VPython,Weave,Cython,HDF5,xlrd,xlwd等内容。增加了几个频域声音信号处理算法。
其他:视频教程缓慢制作中。视频教程将以实例程序的运行演示和一些工具的操作说明为主。由于长期缺乏汉语交流,发现自己的语言表达能力有所下降,录制视频教程比较痛苦。
由于国内的Python用户似乎不多,而且可能许多用户都是以Web开发为主,因此比较担心此书的销量,如果你有兴趣购买此书,或者了解用Python进行科学计算的一些情况的话,请在此留言,过段时间还准备搞一个问卷调查。
用VPython显示3D汽车模型
这本来是《用Python做科学计算 》中的一个章节,由于最近在考虑出版此书,因此许多更新的内容没有放到在线版本中去。
有朋友询问如何显示3D汽车模型,原来的程序是用pyopengl开发的,由于是公司的项目,不能开源。因此我用VPython重写了显示汽车模型部分的代码。现在将这部分内容提前放出来。包括blender的汽车模型,python源程序以及书中相关的章节。
Gawain's Jail
Tweetie and Echofon
我真正有用的twitter客户端主要就是Tweetie和Echofon,各有各的好,但是哪一个也不让我满意。如果这两个产品要是互相学习一下就好了。我希望一个twitter客户端能集如下功能于一身
- 展开一个用户的时候像Echofon拉出一个Drawer
- 可以展开一个关联对话
- 以看官方的retweete
- 可以查看list
- 能使用方向键来选择单个tweete.
- 能使用快捷键进行reply,retweete,direct reply和repost的操作
- 可以对重点用户的tweete打label或颜色标记
March 09, 2010
Gawain's Jail
buzz和twitter代表的是两个方向
注意到Google Reader的People You Followed里老是有几条排在前面,这才发现GReader对目录有三种排序。
- Sorted by newest.
- Sorted by oldest.
- Sorted by magic.
一个人的关注面是有限的,以前的我会把Greader清零才睡觉,但是后来我发现信息越来越多,我放弃了,开始只关注部分信息。同样的问题也发生在twitter上,起初我觉的信息量不够,follow了许多人,但是我同样发现信息量太大了,我处理不了那么多,开始unfo了不少,到了可以接受的情况。
buzz的重点还是在集体的智慧,意在利用Google强大的计算能力和海量的信息,再加上集体的智慧来提供有用的信息。而twitter的重点是实时,过期的信息是不被重视的,保持信息新鲜的方法是被Retweete。
有人的地方就有八卦和政治,而且人们谈论八卦和政治的热情比较高。这一点无论在twitter和buzz里都是有的,twitter的感觉是线性的,过去的就是过去的,不再回来。而buzz则不然,时空回转也不是不可能,几年前的讨论都可能被他人提起,进入你的视线,且提起陈旧或无趣题目的人也许你并没有follow。
buzz带来的到底是惊喜还是搅扰?从目前看来搅扰的成份要大过惊喜。
和出租车司机聊天
前几天搬了次家,路上和出租车司机就聊起天了,聊的主要内容是小产权的房子。据司机说,村里在宅基地上盖房子,审批比较严,但是一旦盖出来了就是村里说了算了。要说这审批也好批,村里以建设新农村,家家户户住楼房为理由也就批下来了。刚开始呢村支书给大家分完了房了,余下的房子就在开始卖。但是村民很快就又买了几套。村支书还在想,这不是刚刚分完房,怎么又买房呢?后来才明白人家村民转手加2000就卖了,然后这村支书就直接把价码提高到了2000,让村里来挣这个钱。村里盖的房子有不少是电采暖,比之市政供暖还是较贵的,但是村里有卖地来的钱,所以就给每户村民补贴电暖。但是村里的宅基地是有限的,卖地的钱自然也是有限的,如果这样补贴,钱总是会贴没的。
在中国村支书是直选的,所以自这个补贴开始之后,就没有那一届村支书敢把这个供暖补贴取消了。
March 01, 2010
Gawain's Jail
说说最近玩iPhone的事
前些日子从朋友那里拿了一个iPhone 3G。拿过来时候基本就是个砖头,推测是一个已经刷到3.1.3的有锁版,后来还拿去e世界的电玩巴士请帮解锁,未成功。回来查了一些资料及刷机的方法,自己也刷了几次。这次经历算是给我补了一把iPhone的课。
iPhone除了1代、3G、3GS的区别之外还有有锁版和无锁版的区别。有锁版一般是美国的和日本的,俗称美版和日版,应该也还有欧版的。国内的无锁版一般都是指港版。有锁和无锁的区别是有没有绑定了电信运营商,美版绑定的运营商是AT&T,而日版绑定的是SoftBank Mobile。正常来说绑定了运营商的iPhone只能使用绑定运营商的sim卡,然而非指定运营商的用户也想使用iPhone,于是就出现了卡贴,把一个非指定运营商的sim卡伪装成一个指定运营商的sim卡。后来有人通过软解的方式把iPhone的这一限制给破了,这个过程也就称之为解锁,但是软解的过程并不是一切顺利的,苹果也是通过更新软件的方式防止人们对iPhone进行解锁。最近的iPhone OS 3.1.3的升级就造成了iPhone 3G和3GS无法解锁的情况(我相信这只是暂时的)。目前iPhone 3G有锁版要是刷到了3.1.3并且baseband升到了05.12.01,那么得到的是一个增强版的iPod Touch。iPhone 3G升到3.1.3之后可以使用PwnageTool定制一个固件,选择不要升baseband,这样起码让iPhone 3G可以当个iPod使用。也可以刷回到3.1.2(这个过程会遇到1015的错误),再使用Blackra1n来解。
iPhone用户经常会提到的一个事情就是JailBreak,称之为越狱。越狱后就可以安装许多Apple Store之外的应用程序了。
iPhone用户经常会做同步操作,其实在同步的时候iTunes还会做备份的操作,如果你换了iPhone,那就可以使用"从备份中恢复"这一招把设置、联系人、Safari的书签等给恢复回来。但是要注意以前iPhone里的mp3、视频和买的应用程序就只能从iTunes中同步才能回来了。
在iPhone的刷机过程中要特别注意恢复模式和DFU模式的区别,最大的区别是DFU模式下屏幕是全黑的。进入DFU模式的方法是如下:
- 关机
- 同时按下Power+Home键不放,保持10秒
- 松开Power键,Home继续不放,保持10秒
- 松开Home键,进入DFU模式
就iPhone刷机升级这个事来看,没事别折腾。如果要折腾有几点忠告:
- 无论何时都不要刷官方的新版,除非你是无锁版的,并且不想越狱。
- 对自己的iPhone要完全了解。是否有锁?什么型号?baseband是多少?。
- 熟读解锁软件的各个注意事项,一定要读,看看自己的手机是不是在可破的范围之内等等。
February 22, 2010
Gawain's Jail
帮助怡帆
看到拯救怡帆:请帮助这位漂亮、坚强的女孩。我自己到今年5月底就会成为一名父亲,深感这样的事情是大不幸,希望怡帆能够挺过去,去拥有她应该拥有的童年。
捐赠方式 1. 银行转账 怡帆妈妈农业银行账户: 户名:周萍 账号:6228480010211053011 开户行:中国农业银行北京市分行白石桥支行 2. 支付宝 怡帆基金支付宝账户:[email protected] 3. 和睦家基金会 (美元捐款)另有网站:http://www.help-yifan.org,网站上也可以看到捐款信息。望怡帆重返健康!
January 12, 2010
HYRY 's Blog
Sphinx中文搜索插件
用Sphinx写文档很爽,用Python做科学计算 就是用Sphinx编译的,但是Sphinx的搜索功能不支持中文,究其原因是因为它不支持中文分词,产生的索引文件searchindex.js中没有正确的中文单词索引。进行分词的程序在Sphinx目录的search.py文件中。此程序使用正则表达式将英文单词分出来,因此只需要将其中的两个使用 word_re变量地方替换为中文分词算法即可。
为了维护方便,我没有直接修改此文件,而是做了一个扩展插件,其源程序如下:
from os import path
import re
import cPickle as pickle
from docutils.nodes import comment, Text, NodeVisitor, SkipNode
from sphinx.util.stemmer import PorterStemmer
from sphinx.util import jsdump, rpartition
from smallseg import SEG
DEBUG = False
word_re = re.compile(r'\w+(?u)')
seg = SEG()
stopwords = set("""
a and are as at
be but by
for
if in into is it
near no not
of on or
such
that the their then there these they this to
was will with
""".split())
if DEBUG:
testfile = file("testfile.txt", "wb")
class _JavaScriptIndex(object):
"""
The search index as javascript file that calls a function
on the documentation search object to register the index.
"""
PREFIX = 'Search.setIndex('
SUFFIX = ')'
def dumps(self, data):
return self.PREFIX + jsdump.dumps(data) + self.SUFFIX
def loads(self, s):
data = s[len(self.PREFIX):-len(self.SUFFIX)]
if not data or not s.startswith(self.PREFIX) or not \
s.endswith(self.SUFFIX):
raise ValueError('invalid data')
return jsdump.loads(data)
def dump(self, data, f):
f.write(self.dumps(data))
def load(self, f):
return self.loads(f.read())
js_index = _JavaScriptIndex()
class Stemmer(PorterStemmer):
"""
All those porter stemmer implementations look hideous.
make at least the stem method nicer.
"""
def stem(self, word):
word = word.lower()
return word
#return PorterStemmer.stem(self, word, 0, len(word) - 1)
class WordCollector(NodeVisitor):
"""
A special visitor that collects words for the `IndexBuilder`.
"""
def __init__(self, document):
NodeVisitor.__init__(self, document)
self.found_words = []
def dispatch_visit(self, node):
if node.__class__ is comment:
raise SkipNode
if node.__class__ is Text:
words = seg.cut(node.astext().encode("utf8"))
words.reverse()
self.found_words.extend(words)
class IndexBuilder(object):
"""
Helper class that creates a searchindex based on the doctrees
passed to the `feed` method.
"""
formats = {
'jsdump': jsdump,
'pickle': pickle
}
def __init__(self, env):
self.env = env
self._stemmer = Stemmer()
# filename -> title
self._titles = {}
# stemmed word -> set(filenames)
self._mapping = {}
# desctypes -> index
self._desctypes = {}
def load(self, stream, format):
"""Reconstruct from frozen data."""
if isinstance(format, basestring):
format = self.formats[format]
frozen = format.load(stream)
# if an old index is present, we treat it as not existing.
if not isinstance(frozen, dict):
raise ValueError('old format')
index2fn = frozen['filenames']
self._titles = dict(zip(index2fn, frozen['titles']))
self._mapping = {}
for k, v in frozen['terms'].iteritems():
if isinstance(v, int):
self._mapping[k] = set([index2fn[v]])
else:
self._mapping[k] = set(index2fn[i] for i in v)
# no need to load keywords/desctypes
def dump(self, stream, format):
"""Dump the frozen index to a stream."""
if isinstance(format, basestring):
format = self.formats[format]
format.dump(self.freeze(), stream)
def get_modules(self, fn2index):
rv = {}
for name, (doc, _, _, _) in self.env.modules.iteritems():
if doc in fn2index:
rv[name] = fn2index[doc]
return rv
def get_descrefs(self, fn2index):
rv = {}
dt = self._desctypes
for fullname, (doc, desctype) in self.env.descrefs.iteritems():
if doc not in fn2index:
continue
prefix, name = rpartition(fullname, '.')
pdict = rv.setdefault(prefix, {})
try:
i = dt[desctype]
except KeyError:
i = len(dt)
dt[desctype] = i
pdict[name] = (fn2index[doc], i)
return rv
def get_terms(self, fn2index):
rv = {}
for k, v in self._mapping.iteritems():
if len(v) == 1:
fn, = v
if fn in fn2index:
rv[k] = fn2index[fn]
else:
rv[k] = [fn2index[fn] for fn in v if fn in fn2index]
return rv
def freeze(self):
"""Create a usable data structure for serializing."""
filenames = self._titles.keys()
titles = self._titles.values()
fn2index = dict((f, i) for (i, f) in enumerate(filenames))
return dict(
filenames=filenames,
titles=titles,
terms=self.get_terms(fn2index),
descrefs=self.get_descrefs(fn2index),
modules=self.get_modules(fn2index),
desctypes=dict((v, k) for (k, v) in self._desctypes.items()),
)
def prune(self, filenames):
"""Remove data for all filenames not in the list."""
new_titles = {}
for filename in filenames:
if filename in self._titles:
new_titles[filename] = self._titles[filename]
self._titles = new_titles
for wordnames in self._mapping.itervalues():
wordnames.intersection_update(filenames)
def feed(self, filename, title, doctree):
"""Feed a doctree to the index."""
self._titles[filename] = title
visitor = WordCollector(doctree)
doctree.walk(visitor)
def add_term(word, prefix='', stem=self._stemmer.stem):
word = stem(word)
word = word.strip(u"!@#$%^&*()_+-*/\\\";,.[]{}")
if len(word) = 1: return
if word.encode("utf8").isalpha() and len(word) 3: return
if word.isdigit(): return
if word in stopwords: return
try:
float(word)
return
except:
pass
if DEBUG:
testfile.write("%s\n" % word.encode("utf8"))
self._mapping.setdefault(prefix + word, set()).add(filename)
words = seg.cut(title.encode("utf8"))
for word in words:
add_term(word)
for word in visitor.found_words:
add_term(word)
def load_indexer(self):
def func(docnames):
print "############### CHINESE INDEXER ###############"
self.indexer = IndexBuilder(self.env)
keep = set(self.env.all_docs) - set(docnames)
try:
f = open(path.join(self.outdir, self.searchindex_filename), 'rb')
try:
self.indexer.load(f, self.indexer_format)
finally:
f.close()
except (IOError, OSError, ValueError):
if keep:
self.warn('search index couldn\'t be loaded, but not all '
'documents will be built: the index will be '
'incomplete.')
# delete all entries for files that will be rebuilt
self.indexer.prune(keep)
return func
def builder_inited(app):
if app.builder.name == 'html':
print "****************************"
app.builder.load_indexer = load_indexer(app.builder)
def setup(app):
app.connect('builder-inited', builder_inited)
这个扩展插件使用smallseg中文分词库进行中文分词。
smallseg中文分词库下载地址: http://code.google.com/p/smallseg
December 31, 2009
Gawain's Jail
终了2009
2009年又要过去了,一年又一年,日子总是追着走。
从工作、学习和生活三个方面去说,2009年做的事真是不多,有些得过且过的感觉了。年初我有许多的计划,可是到了年终,细细的数来却没能完成几样。生活上值得庆祝的事情,一来办了婚礼,二来呢做了准爸爸。工作上没有值得庆祝的事,只有值得反省的事。学习上的事情,是觉的学的太慢了,而且网撒的太大,有点收不住的感觉了。
2010年对自己的希望是:
- 做一个好爸爸。
- 多学一门外语。
- 把学习的重点放在计算机科学上,不要再搞民科了。要深一些!
- 广交好友,提升RP。
- 在人大的学习该有个了结了。
- 多了解一些微观经济学的东西。
- 克服拖沓症。
December 26, 2009
HYRY 's Blog
用Python做科学计算有封面了
终于开始了10天的长假,准备在假期里面好好校对一下《用Python做科学计算》,并完成一些新的章节。 为了感觉更加正规一些,花了点时间做了一个封面。图中的算式 e**(i*pi)+1的值等于0,是一个经典的数学公式,它将圆周率pi, 欧拉常数e, 虚数单位i, 和整数0和1,通过加法 乘法和幂运算结合起了。希望本书也能起到这种大融合的作用。
December 11, 2009
Gawain's Jail
Automator Proxy Toggle Shell
人都是被逼出来的,为翻墙方便,用Automator写了一个Service,就执行一段shell,还设置了一个快捷键。
#!/bin/sh
STAT=`sudo networksetup -getwebproxy Ethernet | head -1 | cut -d: -f 2|sed 's/ //g'`
if [ "$STAT" == "No" ];then
networksetup -setwebproxystate Ethernet on;
/Users/guixing/bin/growlnotify -m "Proxy On";
else
networksetup -setwebproxystate Ethernet off;
/Users/guixing/bin/growlnotify -m "Proxy Off";
fi
growlnotify是Growl的一个命令行工具。
Limodou
mootools发布插件网站
可以在 http://mootools.net/forge/ 上访问到。关于网站发布的声明 http://mootools.net/blog/2009/12/10/the-official-mootools-plugins-repository-is-here/ 。真是不错。不过等2.0还是让人心急啊。
类别:Mootools 查看评论
December 04, 2009
Gawain's Jail
Google的公共DNS服务
Google提供了公共的DNS服务,三金和老黄马上就想到了对CDN厂商的冲击。我看了下Google的Performance Benefits,记一笔。
发生在解析服务器和其它DNS服务器的传输时间,有三个原因。
- 无缓存。无缓存就要查其它的NS。
- 无法服务。要查的NS如果过载,就可能发生请求被丢弃或重发。
- 恶意的流量。DoS,重点是攻击,人为造成第二种情况甚至更严重。
无缓存的情况有一些数据,NS服务器拿到一个无缓存的请求,会导致至少1次的外部NS查询,一般情况会是2次以上。
根据Googlebot的情况来看,平均解析时间是130ms,然而还有4-6%的请求会直接超时,这通常是UDP丢包或服务器无法到达。把丢包,死NS,NS配置错误等因素都计算进来的话,实际的解析时间是300-400ms。
无缓存的情况较难避免,原因有三:
- internet太大而且还在成长。新用户和新网站都在增长,并不是所有的网站都是那么的流行,所以大部分的请求都是无缓存的情况。
- TTL太短,这个好象是个趋势,短TTL带来的就是更多的NS请求。
- 缓存是相对隔离的,NS大多放在LB设备下,缓存是随机的。所以就增加了无缓存的情况。
Google采用了一些方法,如下:
- 提供足够的服务器。
- 避免恶意攻击。
- LB使用共享的缓存。
- 预抓取名字解析。
- 提供全球服务。
December 02, 2009
Gawain's Jail
记一笔keep-alive和cache-control
以前看的时候大多走马观花,补补课,记一笔吧。
- 对于静态内容在HTTP Header中设置过期时间和最大时间,可以有效的使浏览器避免下载已经下载过的文件。
- js,css,图片什么的都是静态内容,都应该考虑cache,但是html不是静态内容。
- Expires和Cache-Control: max-age是资源终身鲜活的Cache控制。浏览器在过期之前不进行资源的鲜活检查。
- Last-Modified 和ETag则是对资源的一种描述,属于启发式的Cache控制,浏览器在检查之后再决定使用Cache与否。
- Expires 和Cache-Control: max-age,作用相同,设置其中一个即可,Last-Modified 和Etag也是冗余的设置,设置其中一个即可。
- 设置Expires,Cache-Control支持率不及Expires。这个值通常设置1个月,不要超过1年。如果不知道过期时间,就设长一点,当发生变化的时候使用URL的指纹。
- 要考虑到代理服务器的Cache情况,使用Cache-Control的public还是private。通常来说要set-cookie的地方就不要让代理Cache,所以设置为Private。
- 代理Cache的情况还有压缩与否的问题,有两种方法,一种是把Cache-Control设置为Private,使代理服务器不Cache这些内容。另一种是设置Vary: Accept-Encoding的Header,这可以使代理Cache两种内容,压缩的与不压缩的。
- 避免Firefox的URL哈希冲突,Firefox的URL哈希算法有8个字符的冲突边界。所以两个资源的URL差异应该在8个字符以上。
- 设置正确的Vary Header,IE对于设置了Vary头的资源是不Cache的,有例外,Vary头的值是Accept-Encoding和User-Agent的时候可以被IE给Cache,所以要么不设Vary头,要么就对Vary头进行裁剪。
- 使用较少的CPU和内存
- 开启HTTP 管道
- 减少网络拥堵
- 在接下来的请求中,减少传输时间。
- 错误可以被报告但是不关闭TCP连接。
在RFC 2617第47页里,一个用户客户端对任何服务器或代理不能维持2个以上的连接。代理可以维持2xN个连接。
IE6和7使用 2个长连接,IE8使用6个,都是在60秒之后超时。 Firefox的长连接都是在300秒超时,同时使用的连接可以自定义(按每主机或总计),Opera与Firefox类似。
December 01, 2009
Gawain's Jail
卧底经济学的小记(1)
还价能力来自于稀缺性。
稀缺有两种,一种是自然稀缺,另一种是人为稀缺。人为的通过政策和法律限制"边际"资源,造成资源的稀缺,进而提高了还价的能力。-
如果1蒲式耳粮食值1美元,那么5蒲式耳粮食就是5美元的地租。如果1蒲式耳粮食值20万美元,那么5蒲式耳粮食就是100万美元的地租。
现行的货币系统,因其本身做为一种商品,其价值的不稳定,对普通大众甚至是有一定的欺骗性。许多人认为货币是稳定不变的,至少认为变化不大,而实际上货币是有时间成本的,是在不断贬值的。当存款的利率低于当年的通货澎胀率,那么把钱存在银行实际上是在赔钱。实际这个例子是在说羊毛出在羊身上,地租的差异是因为地皮的差异,但是地租的高低则是议价的结果。而且地皮的差异并不是一承不变的,比如买房的时候周围还没有地铁,但是后来地铁新建之后就改变了地皮与地皮之间的差异。
November 24, 2009
Limodou
UliPad 4.0发布
本来是懒得发布,因为最新更新也不是很多,不过从3.9发布到现在竟然也有1年多了,3.9发布还是在08年4月份,想不到时间过得真快啊。
Links
- Project: http://code.google.com/p/ulipad
- source version: http://ulipad.googlecode.com/files/ulipad.4.0.zip
- windows exe version: http://ulipad.googlecode.com/files/ulipad.4.0.py25.exe
- maillist: http://groups.google.com/group/ulipad
- ulipad snippets site: http://ulipad.appspot.com (hosted by GAE)
类别:Ulipad 查看评论
November 16, 2009
Gawain's Jail
Wave和科技创新
周末参加了豆瓣举办的Python聚会,直播使用了Google的新产品----Wave,发现Wave真的可以把会议室给解放出来。
刚刚接触到Wave的人,大多都有些失望,发现Wave和一个即时通信工具没有什么两样,只不过组的成员是不固定的。同样也没有带来想象中的信息爆炸。
然而在这次聚会直播中,我们发现了Wave的真正实力,与IM相比Wave多出了这样几个功能。
- 可以在任何时间把一个人拉入一个Wave中。(与其说是Wave不如说是Topic)
- 可以对消息进行再次的编辑、删除操作。
- playback,回放可以让后来的人了解过程或者回顾讨论的顺序,比如讨论过程中拉了谁进来,谁说了什么话,谁修改了自己的或者别人的发言,哪句话被谁在什么时候给删除了等等,Wave让我们了解了这是一个过程。
就上面这些功能就足以让我们不必到会议室进行讨论,而是直接在线上进行交流,快速的讨论,如果讨论过程中觉的某某人也应该参加这个讨论,那么就把他拉进来吧,就是这样,很简单,但是我们有会议记录,可以回放的会议记录。相对于会议室,缺少的可能是一个白板,我相信不久就会有这样的Widget出来。
科技创新改变生活方式,也改变行业的规则。twitter提供了个人的即时广播电台,YouTube提供网络电视,Wave提供了网络会议室,Facebook提供了网络的社会关系。如果有一天机器人可以送快递,我们就真的可以足不出户的生活了。
BTW: 当国际科技发展在改变国际友人的生活方式的同时,国内科技的发展同样的在改变国人的生活方式,比如翻墙。鬼子们通过网络(也许是免费的)看YouTube 1080p高清电影的时候,我们还在为自己1M ADSL付费。
November 12, 2009
Limodou
Uliweb在stdyun的部署说明
stdyun是张沈鹏同学做的主机系统,在开始我申请了他提供了免费试用帐号,主要是想试一下Uliweb的部署。在使用过程中由于开始不太熟悉,获得了张教主的帮助,成功将uliwebproject部署成功,目前可以通过 uliweb.com.cn来访问(由于是试用期,因此可能随时关闭)。这个主机系统创建不久,目前已经开始可以租用,速度真是很快,提供ssh,mysql。下面是我将Uliweb的部署写出来,为Uliweb感兴趣的人提供一个部署的实例。所有尝试以svn中的最新版本为准。
在stdyun上部署Uliweb还算方便。
准备工作
因为stdyun不提供缺省的二级域名,因此需要用户自行去注册一个域名并进行绑定。具体如何申请和绑定
张教主在我的问题中给了很好的回答,可以参考:
http://groups.google.com/group/python-cn/browse_thread/thread/3b00351b97b6690a/bb28c5ec135d1b7b
stdyun环境介绍
一旦你申请帐号成功,stdyun会发送给你有关ssh,mysql的信息,因此你可以使用putty进行登录。具体登录过程不再说明。
stdyun已经安装好了一些环境,比如virtualenv,setuptools, easy_install。并且它所提供的python是最新的2.6.4。你可以认为在你的目录下已经有了基础的python环境了。
virtualenv是一个很方便在一个受限环境下创建一个完整的python的工具,由于stdyun已经安装好了因此你不再需要安装。并且它已经被激活,所以激活这步也不用执行了。直接使用就好了。
bin 目录是存放一些命令,如python,virtualenv的命令行工作,easy_install等。如果你在virtualenv下安装python模块,那么当存在scripts需要安装时,会安装到这个目录下。
lib 用来放置python下的库。安装的python库源文件就放在这个目录下。
Uliweb软件安装
因为你已经有了一个完全由你控制的python 2.6的环境(Uliweb可以运行在2.6下),因此你可以按照Uliweb的安装说明进行操作,完全没有问题。这里我列出通过svn来安装的步骤,这样便于与Uliweb的svn保持同步。
为了方便,你可以在$HOME目录下创建一个src的目录,然后进入这个目录,再在这个目录下通过svn获得Uliweb的代码,如:
1 2 3 4 5 |
mkdir src cd src svn checkout http://uliweb.googlecode.com/svn/trunk/ uliweb cd uliweb python setup.py develop |
这样就安装好Uliweb了。
创建Hello
让我们回到$HOME目录下
1 2 3 |
uliweb makeproject hello cd hello uliweb makeapp Hello |
部署
stdyun是使用fastcgi模式。而Uliweb已经提供了这么一个文件,就在hello目录下。检查一下runcgi.fcgi它的执行权限是否是x。如果不是请修改:
1 |
chmod +x runcgi.fcgi |
然后要修改一下runcfi.fcgi,主要是第一行改为:
1 |
#!/home/vhost/s63/bin/python |
修改完毕,然后就需要在stdyun的控制面板添加url与handler的对应关系。
绑定
进入: http://stdyun.com/vhost/my
在下面的绑定域名处添加你申请的域名,如demo.uliweb.com.cn,然后点击绑定域名。

输入后进入目录绑定界面。我们想通过 demo.uliweb.com.cn来访问hello项目。配置如下:

输入后点添加即可。
然后过一会再访问你的域名。如 http://demo.uliweb.com.cn 你会看到一个Hello, Uliweb的信息显示出来了。
类别:Uliweb 查看评论
November 05, 2009
Limodou
uliweb.com.cn
感谢张教主的帮助,不过现在还有一点点小问题,因为有些包还没装上。不过首页已经可以访问了。uliweb已经在张教主的stdyun上部署成功了。几点事项: http://groups.google.com/group/python-cn/browse_thread/thread/3b00351b97b6690a# 声明,因为我使用的是免费试用,因此可能用的时间不会太长。
域名(我去的9host.cn申请的,. com.cn 只要3块钱,续费要50元)
有了域名要设置对应的IP(IP为:119.88.56.193),具体见张教主的说明(同时要注意修改9host的DNS时要使用IE浏览器。 )
然后runcgi.py需要将后缀改为.fcgi。 不过这个我要再更新一下uliweb。
回头我会写一个更详细的uliweb在stdyun上的部署说明。
类别:Uliweb 查看评论
November 04, 2009
Limodou
Uliweb之Cache
在经过对beaker中的session替换之后,我终于又把cache给替换掉了。完全是自个儿重写。一方面它可以象一个dict一样工作,同时可以通过put, get来调用。使用这两个函数的好处就是可以有更多的参数。目前这个类在uliweb/lib/weto/cache.py中。 创建cache import weto.cache cache = weto.cache.Cache() 这样可以创建一个cache。因为没有指定Cache类的初始化参数,因此会自动以file格式创建cache。如果需要指定其它的格式和参数,可以设置: storage_type, options, expiry_time 这三个参数。storage是类型,目前只支持'file', 'dbm', 'database',分别对应三种不同的存储类型。 options则根据不同的类型有所区别,比如'file'类型需要传入'data_dir',用以指定cache保存的路径。而'database'则需要指明要使用的表名和数据库连接的一些信息。 expiry_time是指定缺省的超时时间。这是当你在put时没有指定超时时间时使用的,在调用put时可以单独设定。 cache.get(key) 这样的调用,如果key不存在,或超时则会引发一个异常抛出CacheKeyException异常。 如果不想引发异常,则可以: cache.get(key, default) 其中default不能为None,这样当key不存在,则不会引发异常,返回default值。如果为None,则同get(key)的效果。 cache.put(key, value, expire=None) 这样可以设置一个cache。如果expire没有传入则使用缺省的超时时间。时间以秒为单位。 同时为了方便函数的封装,还提供了 cache.cache(key=None, expire=None) 这个decorator。例如: @cache.cache(expire=15) 或 @cache.cache(key, expire=15) 这两种都是可以的,区别在于前一个没有key参数,那它将根据函数名和参数来生成一个key,而后面则是由用户主动指定了一个key。 在进行上进的改造之后,原来的beaker就删除了,这样uliweb中不再使用beaker了。同时对原uliweb.contrib.cache进行了修改,去掉了middle_cache.py,而采用让用户自行调用的机制。同时为了同app的配置功能相结合和方便用户使用,在uliweb/utils/cache.py中编写了一个get_cache()的函数,同时对Cache类的增加了page方法。 get_cache()可以自动从settings中找到相应的配置。目前主通过两个secion来控制的: [CACHE]和[CACHE_STORAGE],前者用来控制cache的类型和超时时间。后者是用来针对每一种类型来设置与存储相关的配置信息。在调用get_cache()时,你还可以传入一些参数,它的原型是: def get_cache(cache_setting_name='CACHE', cache_storage_setting_name='CACHE_STORAGE'): 即可以指明使用其它的配置名,这样就可以在你的settings.ini中存放不同的cache的配置,通过get_cache来使用不同的cache机制。 为什么要对Cache进行扩展,Cache.cache原来是针对函数本身和它的参数,但是这样对于view有一点问题。有些view可能通过QUERY_STRING来处理不同的传入参数,因此在url上它们不同,但是在view函数上是完全一样,因此这种只根据函数本身和参数是有问题的。因此扩展的page这个decorator使用了request.url值,它是一个完整的访问路径,包括了QUERY_STRING信息。因此为了生成静态cache,可以使用改造后的Cache类。当你调用get_cache()时返回的cache对象已经是使用了这个新的Cache类了。 所以为了方便和更适合在Uliweb环境下使用,可以使用uliweb.utils.cache的get_cache()函数。例如: 现在我把uliwebproject也添加了cache的支持,不过发现的问题是,不能简单的使用@cache.page()来对view方法进行处理。原因是: 在view方法中有对cookie的处理,采用cache的方式会屏蔽掉这块处理 因此在uliwebproject中并不是使用的decorator的方式,而是在view中对可以cache化的部分进行了手工处理,如:
def f(*args, **kwargs):
def f(*args, **kwargs):
1
2
3
4
5
6
from uliweb.utils.cache import get_cache()
cache = get_cache() #使用缺省的settings.ini设置。因此需要加入uliweb.contrib.cache这个app
@cache.cache(expire=15)
@expose('/index')
def index():
return {}
1
2
3
4
5
6
7
8
9
10
11
12
cache = get_cache()
@cache.cache(_f)
def f():
content = file(_f).read()
if render:
content = to_html(template(content, env=application.get_view_env()))
else:
content = to_html(content)
return application.template('show_document.html', locals())
response.write(f())
return response
类别:Uliweb 查看评论
November 02, 2009
Gawain's Jail
那个洞
在Practice of System and Network Administration中有一章是Climb out of the Hole。这个洞就是:
一个家伙掉到了一个深到他不可能出来的洞里。他听到有人来了,然后他引起了那个人的注意。那个路人听完了他的境况,想了一会儿,也跳进了那个洞。
"你为什么要这样做?现在我们都被困在这儿了。"
"呃〜至少你现在不再孤独了。"那个路人说。
Limodou
uliweb性能之优化思考
性能与功能的确有些矛盾。因为开发uliweb更多是从功能上考虑,因此在性能上我一直没有太仔细测试和分析过。最近找了一个主机部署了一下,别人告诉我刷新一下CPU占用很高,于是我想有机会的确还是要好好搞一下。于是加了一些跟踪,发现了一些问题: 1. get_apps() 的问题 因为uliweb是采用app方式来组织,而且app是允许使用python的包形式。在启动时,为了查找app下的settings.ini和config.ini等信息,使用的是pkgresource的resource_filename,它是要导入才可以的。但是一个导入可能会使得加载变慢。这块的确有些问题。为了查找包的目录,因此要导入,但是后面的处理未必会使用这个包,显得有些浪费。因此我修改了这块处理。如果包是由a.b.c这样形式构成的,我会只导入a,后面两个直接根据a的目录生成一个路径。这样只要保证a的__init__.py中没有太多的耗时的代码就可以了。这样优化后减少了一些时间。 2. pytz的问题 因为uliweb的ORM会处理时区的问题,而且我写了一个utils/date.py模块专门来处理时区转换。因此在启动时,为了省事,我自动导入了date.py模块,它会自动导入pytz模块。但是我发现pytz的导入非常慢。这样造成整个uliweb的启动变慢。因此这块我直接去掉了,让用户自已来处理好了。 3. 可能会引起问题的地方。app的__init__.py文件。因为考虑有些bind的代码会写在__init__.py中,因此在启动app时会自动导入所有app。因此如果有app在这里写了很耗时的代码会影响整个uliweb的启动速度。也许你会认为不好,不过uliweb已经提供了许多静态化的方法,如:bind和expose可以静态化,即在settings.ini中进行配置,这样__init__.py中可以是空的。 这里的问题主要是由于方便性考虑产生的:采用自动化的方式,减少用户的导入或初始化的工作,结果使得处理范围扩大化,影响启动效率。 注意我说的主要是启动时的效率,一旦启动不退出,效率要好一些。 因此uliweb如果每次都是重新启动必然会造成性能下降,比较好的方式还是驻留式,不要每次启动。象mod_wsgi, fastcgi应该是可以支持的。是不是自带一个web server采用反向代理会更好呢?象java一样。
类别:Uliweb 查看评论
October 27, 2009
HYRY 's Blog
一个月统计
用Google Analytics对【用Python做科学计算】的访问量做了一个月的统计,本站和GAE站合计有786位访问者,1300人次访问,4000次页面访问。
搜索次数最多的关键词是“Python 科学计算"和"scipy"。访问最多的页面是numpy和scipy的介绍。
目前rst的源文件大小共244.7k字节。11月份的编辑重点将放在matplotlib和scipy的介绍部分。另外预计完成一篇关于在数字信号滤波器的应用的章节。
October 18, 2009
Limodou
新的uliwiki项目
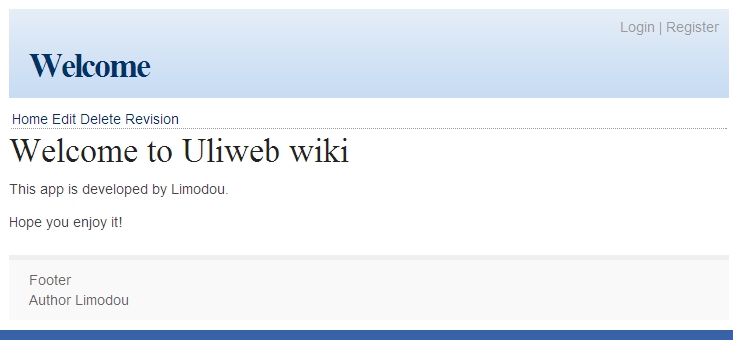
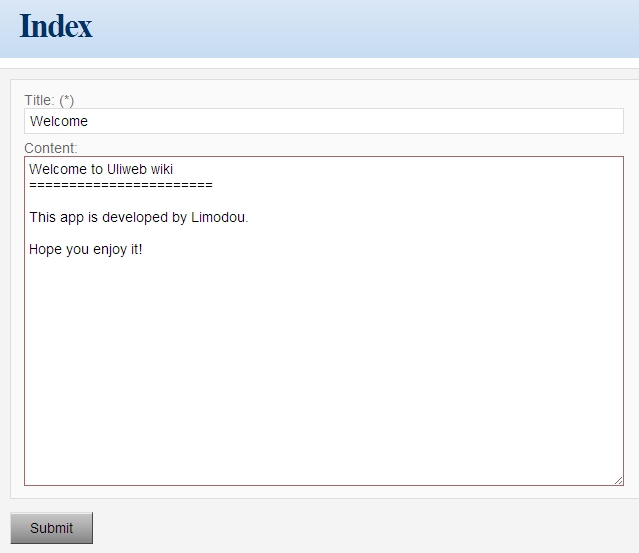
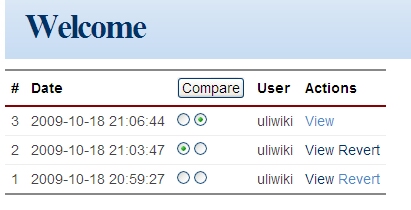
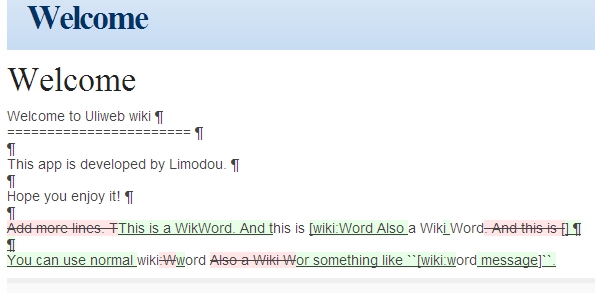
今天开发了一个新的uliwiki的项目,不错是今天,我是照着 http://code.google.com/p/django-wikiapp/ 这个项目来做的,不过象界面,象处理许多都是重写的.因为原来的项目功能挺多,我目前还实现不了,比如:comment, tagging, notification, feed等.目前只是实现了一个基本的wiki的功能,用户认证还没有.但是wiki的功能基本上都全了: 比如生成WikiWord链接,同时支持象[wiki:name message]的wikiword方式. 使用reStructuredText格式(目前只支持这一种) 编辑,删除,版本管理,恢复旧版本,查看旧版本. 其中版本管理我做得比较简单,我是每次保留全部内容,而不是增量内容,主要是为了方便生成版本差异.而django-wikiapp是保存的增量内容,因此处理上要复杂一些. 同时通过研究django-wikiapp发现了 http://code.google.com/p/google-diff-match-patch/ 这个好东西,可以用来生成比较后的结果,并且还可以生成patch. 下面上几张图,看下效果: 这是进入的首页面. 这是某个页面的编辑页面 这是版本信息,先选中不同的版本,然后点上面的Compare按钮可以显示下面的比较结果. 这是使用了google-diff-match-patch显示的结果,还不错. 现在uliwiki的地址在 http://code.google.com/p/uliwiki/ 有兴趣可以试试和完善它.
类别:Uliweb 查看评论
对《I have a dream》的回复
原文: http://j-lite.net/blog/2009/10/17/i-have-a-dream 以下是我的回复: 我也不是为了争uliweb要比django强大,我也说了uliweb有自已的优势,而且我认为比django强的,但django也有它的优势。而且我也在邮件列表中多次声明,每个框架代表一种哲学,不同的哲学引来不同的用户,所以我离开django也可以说是我的哲学与django的哲学区别越来越多造成的。 至于造轮的问题,因此我还是建议你有时间多了解一下uliweb。在今年9.5日的大会上我列举了自已创建的轮子的例子,比如: 整个核心的处理完全是自已写的,它是一个框架的灵魂,负责整个框架的启动,组件管理(app管理),配置管理,request和response处理,middleware的处理,这是每个框架不同于其它框架的核心,是无法复制的。如果只是简单的复制,那么这个框架存在的意义就没有了。其中整个app的详细支持是借鉴了django的思路,但是由我完善的。还有象view的处理,借鉴了web2py的思路,但是自已实现的。详细代码可以见uliweb.core.SimpleFrame.py. 还有许多的模块是我自已写的: 1. web2py的模板,已经被我改造增加了象编译文件目录支持,自定义tag支持,block的支持,这些都是原模板没有了,已经是uliweb化的组件了。 一个框架主要完成的功能其实不外乎:url处理,request, response,view,orm,组件管理,配置管理,提供一些实用的扩展。因此,你可以看到,从架构设计,从组件的实现,许多方面都有uliweb自已的实现,甚至完全是uliweb自已的实现。因此从web2py,从django,从werkzeug,从sqlalchemy更多不是简单的引用,而是思想的借鉴,是更多的封装。 所以,许多东西并不是简单了解就好象明白的。这是我想要澄清的地方。别人不认可uliweb没关系,很正常。但是我只是希望,评论一个东西首先要对它多少深入地了解一下,哪怕与作者交流一下也好,而是不看些表面。不仅从合理客观的角度来谈论一件事,更是不会误导别人。所以uliweb绝不是简单地组装出来的一个东西,它有自已特性甚至独一无二的东西。许多人一谈uliweb,就是从重装造轮的角度,但是他们并不了解许多uliweb上的设计的东西,也基本上没有在技术细节上的讨论,谈得很泛泛。这样对谁都不是公平的。 你所说的框架其实目前pylons和tg都差不多,而uliweb也是可以,django也是可以,只不过pylons和tg可能从组件上可以直接选择,而uliweb,django是可以自已定制开发,不能直接使用。而且你所说的更接近于某些人更偏重于自已去建,比如这篇文章: http://pythonpaste.org/webob/do-it-yourself.html 自已建是没有问题。因此框架更多是给那些不希望,甚至不能够自已来做这件事的人准备的。但是自已建,可能需要了解的东西更多,正如我在构建uliweb过程中,我学到了比以前简单使用框架更多的东西,我甚至做了许多以前不知道自已还可以做的事情。各有各的乐趣。
2.dispatch模块,完全是自已写的,实现类似于django signal的功能。但是整个实现是从ulipad发展来的,没有照搬任何人的东西。
3.i18n也是自已写的,是从ulipad发展来的。
4.weto是在我发现beaker这个session库有问题之后重写的,完全是uliweb的东西。
5.contrib下的所有组件都是我自已写的。
6.pyini完全是自已构思创造出来的,用于处理uliweb的配置文件。
7.orm这块是从头一点点构建的,也是一个框架很重要的部分。
8.form库也是自已一点点写的。
9.url映射的处理机制是使用了werkzeug的route为基础实现的,但是只是使用了它的基本功能,主要功能是uliweb实现的。
类别:Uliweb 查看评论
October 17, 2009
Limodou
关于Webob无法支持flash文件上传问题的记录
根据邮件列表中的回复加工
1. 提出问题:
使用webob在处理通过fancyupload上传的文件,发现会系统挂起,但只要先把request.body读出来就没有问题。因此在uliweb中,将原来使用的webob去除,改成了werkzeug来处理了。
2. qiangninghong的试验:
因为limodou反应的这个问题认为是cgi模块有bug导致的,所以很重要。今天晚上稍稍有点时间,写了一个测试程序来验证一下,但是发现似乎没有这样的情况?
测试代码在这里 http://code.google.com/p/hongqnlib/source/browse/
就是照着 FancyUpload 的 Attach File demo 页面 ( http://digitarald.de/project/fancyupload/3-0/showcase/attach-a-file/ ) 翻译了一下。运行 server.py 后,访问 http://localhost:5002/ ,上传了几个文件,都没有出现挂住的情况啊?
难道是我的这个测试有什么问题?请 limodou 帮忙看看。
3. 我的试验:
我把你的程序改了一下:
1 |
import os |
1. 使用你的程序的确没有问题,使用我改的程序就有问题
2. 两个差别在于你在调用处理前使用了一个StaticURLParser,而我改后的程序是不使用它,在app中自已处理。这样的目的并不是使用StaticURLParser不行,而是这样的做法其实是在app处理前多了一层处理,那么这层处理会影响后面的处理,掩盖问题的发生。
3. 在我的例子中,只要把# logging.error( repr(request.body))这行的注释去了,程序就正常。
4. 原因就是,只要你想办法在执行request.POST['Filedata']之前执行了象request.body之类的代码,这样会引起对body的整个读取,这时读取是按Content-Length来处理的,并且会放在缓冲区中,因此后续的处理就是从这个缓冲区来的了,因此缓冲区最后有没有回车换行是没有关系的。而使用flash控件上传文件,文件体示例如下:
ERROR:root:'------------ei4GI3ei4Ef1Ef1GI3ei4Ij5GI3GI3\r\nContent-Disposition:
form-data; name="Filename"\r\n\r\na.c\r\n------------ei4GI3ei4Ef1Ef1GI3ei4Ij5GI3G
I3\r\nContent-Disposition: form-data; name="Filedata";
filename="a.c"\r\nContent-Type:
application/octet-stream\r\n\r\n#include
<stdio.h>\r\n\r\n------------ei4
GI3ei4Ef1Ef1GI3ei4Ij5GI3GI3\r\nContent-Disposition: form-data;
name="Upload"\r\n\r\nSubmit
Query\r\n------------ei4GI3ei4Ef1Ef1GI3ei4Ij5GI3GI3--'
可以看到,最后是没有\r\n的。这不是浏览器的问题,是flash组件本身的问题,相关的flash的类本身的问题。但其实也不算一个问题,因为cgi的处理是基于multipart的boundary需要以\r\n结束这个假设,但这种假设在某些情况下有问题。相应的cgi的代码如下(从cgi.py中找到的703行):
1 |
def read_lines_to_eof(self): |
因此前面的问题就是,如果不先执行request.body,则后面的request.POST['Filedata']会从流中进行读取,而不是缓冲区中,但flash正好又不返回\r\n,因此server在使用readline就停处了,造成挂起,进而引发浏览器的flash控件的超时。
而你的例子使用了StaticURLParser,可能会进行request.body的读取,所以掩盖了这个问题。当然它到底怎么做的,我没有继续深究。因此我改了你的程序,就是为了不让其它的因素干扰,问题就暴露出来了。
类别:Uliweb 查看评论
October 15, 2009
Gawain's Jail
又一次败家Canon 450D
终于入手了本人的第一台数码单反机。败家记录如下:
- Canon 450D单机,¥3850。
- Canon Lens EF 50mm f1.8 II,¥700。
- SanDisk Extreme III 4GM,¥150。
- Kenko UV,¥70。
- 普通包一个,¥70。
- 3'屏贴一个,送。
半年前,岳父给我了一个美能达X300的单反和一个VR神镜,胶片机的,还有一些很老很老的设备,比如红梅的机器。可惜,到现在一次也没有用过。
Limodou
Uliweb中ORM的新变化
最近一段时间一直在忙着ORM的优化,其中有几点:
1.增加__table_args__的配置。它和__tablename__一样是定义在Model类中的,可以用来增加在执行Table时添加新的一些参数,如果你使用mysql,可以如下定义:
1 |
class Todo(Model): |
2.增加OnInit类方法的调用。这个方法是交给用户来定义的,可以用来执行在执行完Table之后的一些初始化操作,它将在建表之前。比如:
1 |
@classmethod |
3.考虑缺省order_by的实现。但是想用户完全可以在Model中定义相应的方法来实现,类似于django的Manager的东西,比如:
1 |
class Todo(Model): |
4.最重要的一个特性。增加表的注册,并且注册的表不一定是一个Model,而是一个模块名的形式,如以下两种都是正确的注册方式:
1 |
set_model(Model, tablename='user') |
1 |
User = get_model('user')
|
1 |
Reference('user')
|
但是这种get_model()的方式要依赖于set_model()的注册过程。注册有几种方式:
1. 在导入Model文件时,随着Model的class的创建自动会调用set_model()来注册,因此只要正常导入相应的模块,就可以使用get_model()方法了。这种情况下,对通常的开发没有什么影响,用户甚至不必使用这种方式。
2. 由框架来注入。也就是uliweb来实现。这种方式首先要求将Model信息写入到settings.ini中,比如:
1 |
[MODELS] |
然后在某个地方,如views.py中使用get_model()或导入models.py时,就可以自动生效了。
你可能会问,这有什么用呢?一般不都是直接导入来使用吗?完全够用了。
的确,一般的程序的确是根本用不上。但是Uliweb是一个框架,它要考虑代码的复用和替换的问题。考虑一下,在你的models.py可能需要对User表进行处理,那么你会去导入它。但是有可能这个User表不适合你的应用了,你怎么办?并且这个User表不是你自已写的,而是框架或别人提供的,别人可能还要依赖于这个表。因此简单的直接修改并不一定是好办法,因为它可能不受你的控制。重新写一个可能是好办法,但是因为直接导入的原因,比如你是通过:
from uliweb.contrib.auth.models import User这可是直接hard code了,所以重新写必然还要修改导入的代码。那么要解决这个问题,可以采用的一种办法就是将外部依赖的内容配置化,和java中的注入依赖有些象。也就是我在定义自已的东西时,可能需要外部的东西,那么我并不直接导入,而是通过一种获取的方式来得到。这样工并不需要知道外部的组件的实际位置,这件事由框架来完成。因此uliweb现在实现的get_model就是为了实现这一配置化而设计的。
其实现在,象bind,expose都已经是可以配置化的了,都可以放在settings.ini中。如果完全配置化,将可以减少启动时的导入处理,并且替换会很容易。
类别:Uliweb 查看评论
pyini.py的新功能
pyini.py是处理Uliweb的settings.ini的模块,今天向它添加了三个新的方法:set_var, get_var, del_var,它们的特点集中在第一个参数,它可以是'/'分开的字符串,如:'DEFAULT/flag',它相当于: s = ini.add('DEFAULT') 注意,它只支持一层的'/'切分,如:'DEFAULT/flag/name'相当于 'DEFAULT'和'flag/name'。
s['flag'] = True
类别:Uliweb 查看评论
关于《谈谈我对Uliweb的看法》的回复
原文: http://j-lite.net/blog/2009/09/28/lets-talk-about-uliweb 回复如下: 首先感谢对Uliweb的批评。 以下要澄清: 1. 其实所有的框架都是大杂烩,django也不利外。而且别人做好的东西,如果没有什么问题,拿过来用当然就可以了。特别象是框架,它更多的是提供管理模式和一些工具,本身就是个大杂烩。 2. 大一统是不可能的,正如世界上有那么多可以统一的东西为什么没有统一,如:语言,操作系统,数据库?因为多样性才是这个世界的特点。更因为人们总有不同的思念和需求。 3. 为什么不向django和web2py做贡献?贡献我的确做过,如果你去查django和web2py相关的内容,应该还有我的名字。但是有些东西是不可调合的,比如对设计的一些看法,对一些组件的使用,这些东西我建议过,他们并不接受。所以只有以自已的方式来构造。 重新构造也是一个很痛苦的过程,但是可以让造出来的东西完全按自已的意愿发展,也是一种不错的选择。更有一些人不建议使用框架,而是使用组件,为什么,就是不想被框架所束缚。 而你所说的插件系统,就是uliweb实现的一个目标。uliweb的app的功能要比django还要彻底。如果有兴趣欢迎与我交流。
类别:Uliweb 查看评论
October 13, 2009
Gawain's Jail
老婆怀孕了
十一检查出老婆怀孕了,我要做爸爸了。开出一个新的blog-白宝宝诞生记,用来记录孩子从孕育的过程。我很激动!
Powered by Planet!
Last updated: 2010-09-15 16:32:53 CST